Spring Data JPA
N+1
stophyeon
2024. 2. 18. 15:11
728x90
N+1 문제란
N+1문제란 연관관계 매핑된 객체를 조회하는 서비스 메서드 실행 시 생성되는 Query문의 개수가
조회된 데이터의 갯수(n)만큼 추가적으로 발생하는 것입니다.
위 문제는 DB의 조회 성능을 저하시키기 때문에 반드시 해결해야하는 문제입니다.
N+1문제의 원인은 연관관계가 매핑된 Entity(1:N or N:1)의 조회 Query를 실행 시 Entity내부에서 연관관계 매핑된
Entity를 조회하는 Query를 추가적으로 실행하는 것입니다.

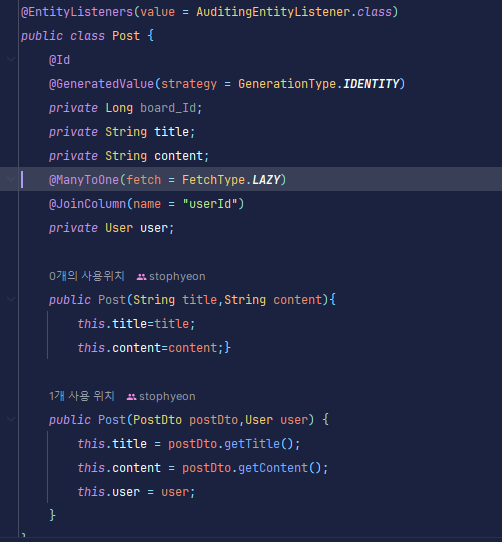

위의 코드에서 2개의 Entity인 Post와 User는 1:N의 연관관계로 매핑되어있습니다.
연관관계의 주인은 FK를 가지고있는 Post입니다 이제 FK를 통해 Post를 조회하는 메서드에서 실행되는 Query를 보겠습니다.

위의 메서드에서 Query 메서드가 3번 실행되므로 Query문이 3번 나오는 것을 확인할 수 있습니다.
그러면 N+1이 발생하지 않은건데 왜 발생하지 않았을까요?
이유는 지연로딩을 사용했기 때문입니다. Post Entity의 ManyToOne(fetch=FetchType.Lazy)가 지연로딩을 선언한 것입니다. 지연로딩을 사용하면 연관관계가 매핑된 Entity를 조회시에는 Query문이 추가적으로 나타나지 않지만
가져온 Entity의 하위 Entity(Post->상위 Entity, User-> 하위 Entity)를 참조할 때 Query문이 나타납니다.
그렇다면 하위 Entity를 사용하는 부분을 쓴 뒤에 Query문을 살펴 보겠습니다.


위의 Query문의 개수가 3개입니다. 추가적인 Query문이 발생하지 않은 이유가 무엇일까요?
이유는 영속성 컨택스트에 현재 가져온 Post Entity의 User객체가 저장되어 있기 때문입니다.
N+1문제가 발생하는 상황을 정리해보겠습니다.
1. 즉시로딩을 사용해서 연관관계가 매핑된 Entity를 조회
2. 지연로딩을 사용해서 연관관계가 매핑된 Entity의 하위 Entity를 조회(단, 영속성컨택스트에 하위 Entity가 있으면
추가적인 Query문없이 영속성 컨택스트에서 Entity를 가져옴)
해결 방법
이제 해결방법을 알아보겠습니다.
해결하는 방법은 Fetch Join을 사용하는 것입니다. 많은 글에서 해결방법으로 알려줍니다.
하지만 RDBMS를 잘 이해하지 못하신 분들은 Join에 대해서 먼저 아셔야 합니다.
저번 글을 보시는 것을 추천드립니다
첫번째 해결방법으로는 Query문을 직접 작성하는 것입니다.
Query문을 직접작성해서 Join문을 사용하는 것입니다.
Query문을 직접 작성하는 방법으로는 @Qeury() 어노테이션을 사용하는 방법과 QueryDSL을 사용하는 방법이 있습니다.
하지만 첫번째 방법은 메서드마다 직접 Query를 작성해야 하므로 반복적인 작업이 많습니다.
그래서 2번째 방법을 추천드립니다.
2번째 방법은 @EntityGraph 어노테이션을 사용하는 것입니다.
@EntityGraph(attributePaths={"Column명"})으로 Column명을 포함한 데이터를 조회합니다.